
Datenaufbereitung & EDA [Teil 1]: Automatisierung ohne Programmierkenntnisse
Wie kann man die Datenaufbereitung für Finanz- & Risikoprozesse durch Python beschleunigen? - Ohne Programmierkenntnisse!
Die Datenaufbereitung ist ein wesentlicher, aber oft langatmiger erster Schritt für tiefgreifendere Datenverarbeitungsprojekte wie bspw. bei Risikoanalysen oder der Anwendung von Machine-Learning in Prozessen. Die Aufbereitung umfasst u.a. das Auffüllen fehlender Werte, das Überprüfen von Datentypen, die Aggregation von Daten, das Erstellen von Pivot-Tabellen, usw. bis die Daten das gewünschte Format haben. Die beliebtesten, branchenübergreifende Tools dafür sind Spreadsheets wie MS Excel oder Google Sheets.
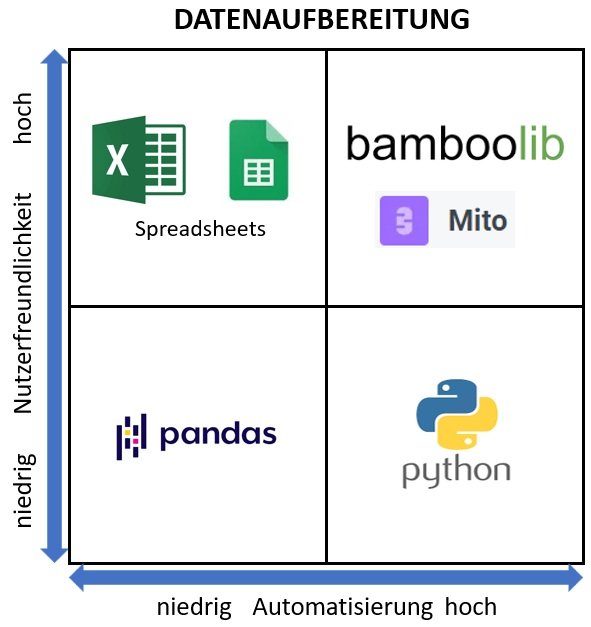
Herkömmliche Spreadsheets haben jedoch auch viele Nachteile, da sie nur begrenzte Möglichkeiten der Automatisierung, der Einbindung in andere Systeme und bei der Erstellung von Änderungshistorien bieten. Daher möchten wir hier zwei Python-Bibliotheken vorstellen, die Ihnen helfen, den Komfort der Excel-Benuterzoberfläche beizubehalten und gleichzeitig Ihre Datenaufbereitung in den Gesamtzyklus des Datenprojekts zu integrieren.
Obwohl Pandas die bekannteste Python-Bibliothek für die Bearbeitung tabellarischer Daten ist, ist sie auch für ihre umständliche Handhabung bekannt. So kann mit den zu verarbeitenden Daten nur durch zuvor erstellten, rigiden Code interagiert werden; genau das Gegenteil von ein paar simplen Verarbeitungsschritten in Excel. Glücklicherweise helfen hier die Python-Bibliotheken “Bamboolib” und “Mito”. Sie bieten dieselbe Interaktivität von Excel und erstellen zusätzlich Code für die Automatisierung und Versionierung (im Hintergrund). Dabei wird ein sog. „Low-Code“-Ansatz verfolgt, bei dem der Benutzer über keinerlei Programmiererfahrung benötigt.
Bamboolib und Mito lesen Datensätze im CSV- oder XLS-Format ein. Zeilen und Spalten können ähnlich zu gewohnten Excel-Verarbeitungen durch Filter, Berechnungen, Aggregation, Validierungen usw. in einem beliebigen Code-Editor mit Markdownunterstützung (bspw. Jupyter Notebook, Visual Studio Code oder im Webbrowser) manipuliert werden. Das Beste daran ist, dass dabei der zugehörige Python Code für jeden Transformationsschritt automatisch im Hintergrund entsteht und jede Aktion des Benutzers in einer Historie dokumentiert werden kann. Damit wird die Datenaufbereitung nachvollziehbar automatisiert und beschleunigt.
Dank Bamboolib oder Mito muss die Datenaufbereitung also nicht mühsam sein, sondern kann einfach automatisiert und versioniert werden.