
Rekurrente Neuronale Netze RNN [Teil 1]: Was ist das?
Was sind Rekurrente Neuronale Netze?
Einleitung
Rekurrente oder rückgekoppelte Neuronale Netze (RNN) sind eine Art von Deep-Learning Modell, die die Fähigkeit besitzen, langfristige Abfolgen zu lernen und daraus die nächsten Schritte vorherzusagen. In diesem Blogbeitrag werden wir uns einige der grundlegenden Konzepte hinter RNNs ansehen und erkunden, d.h. wie sich ihre Neuronen und Architektur von herkömmlichen Neuronalen Netzen unterscheiden.
Allgemeiner Aufbau
Bei einem RNN sind die Neuronen sequentiell miteinander verknüpft. Das Besondere an dieser sequentiellen Verknüpfung ist, dass jedes Neuron Vorinformationen an das Nächste weiterreichen kann. Dies geschieht über den sog. Hidden State den jedes RNN-Neuron besitzt, welches somit ein mathematisches “Gedächtnis” bildet, das lange Abhängigkeiten in Daten erlernen kann.
Ausblick Anwendungen
RNNs sind speziell für die Mustererkennung in sequentiellen Daten entwickelt, d.h. Daten, die eine feststehenden Reihenfolge habe und wo die Abfolge selbst Informationen enthält. Im Bereich Finance, werden RNNs zum Forecasting von hochfrequenten Marktdaten wie Aktien- und Wechselkursen verwendet. Wie alle Deep-Learning Modelle brauchen auch RNNs eine große Datenmenge, aber haben auch eine wesentlich besser Prognose-Performance als herkömmliche statistische Modelle.
Ein weiteres Beispiel von komplexen Daten mit fester Reihenfolge ist die menschliche Sprache selbst. RNNs in der Sprachverarbeitung werden eingesetzt für Auto-Completion, um das nächste Wort in einem Satz vorzuschlagen; oder für KI-Übersetzung, bei der eine Sequenz an Worten von in eine andere Sprache übersetzt wird.
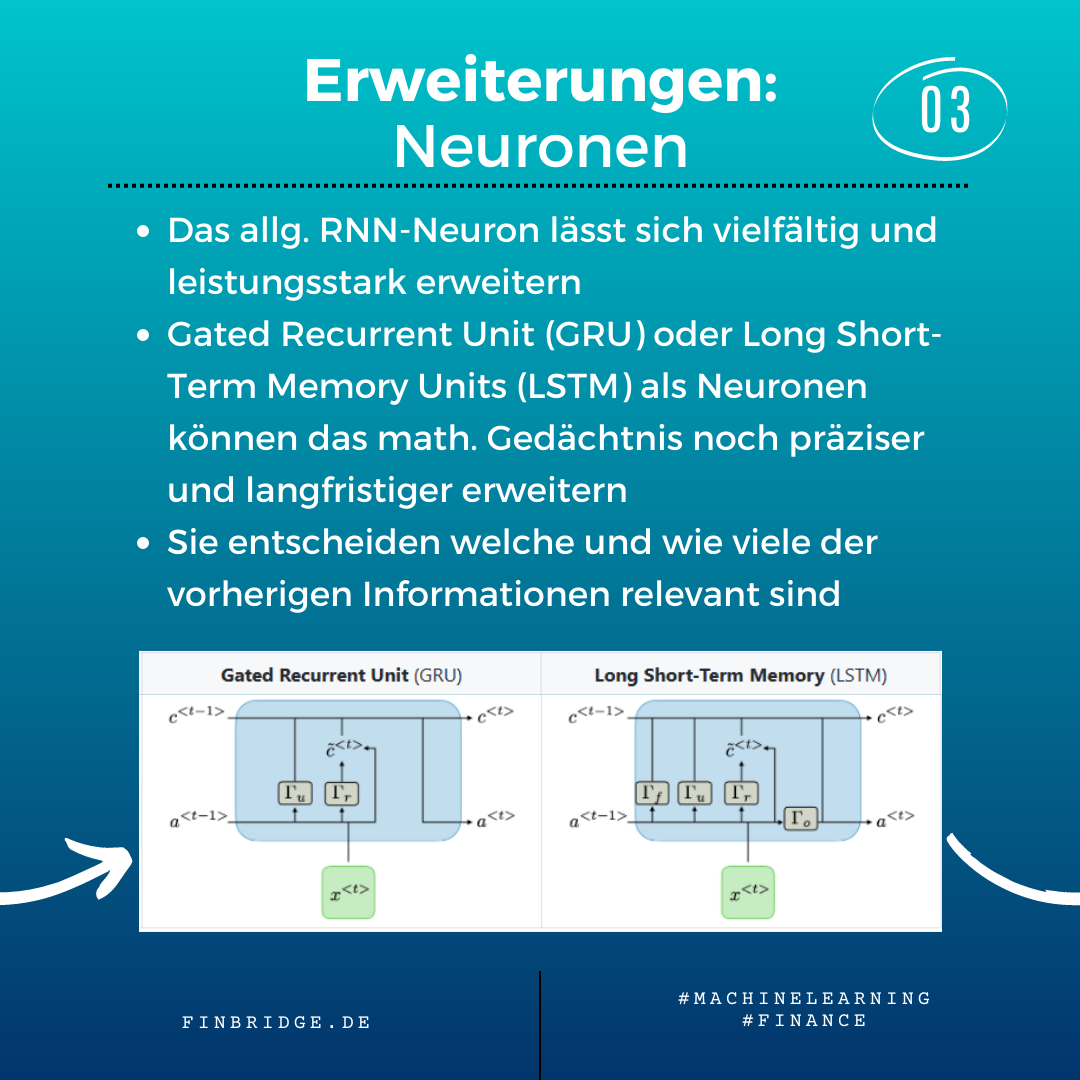
GRU und LSTM
Der Hidden State eines RNN-Neurons kann durch diverse mathematische Funktionen erweitert werden, um die Gedächtnis-Kapazität noch größer und flexibler zu machen. Gated Recurrent Units (GRU) oder Long-Short Term Memory Units (LSTM) als Neuronen können lernen zu berücksichtigen welche und wie viele der Vorinformationen relevant sind bei jedem Berechnungsschritt. Nicht mehr relevante Vorinformationen können somit auch wieder vergessen werden.
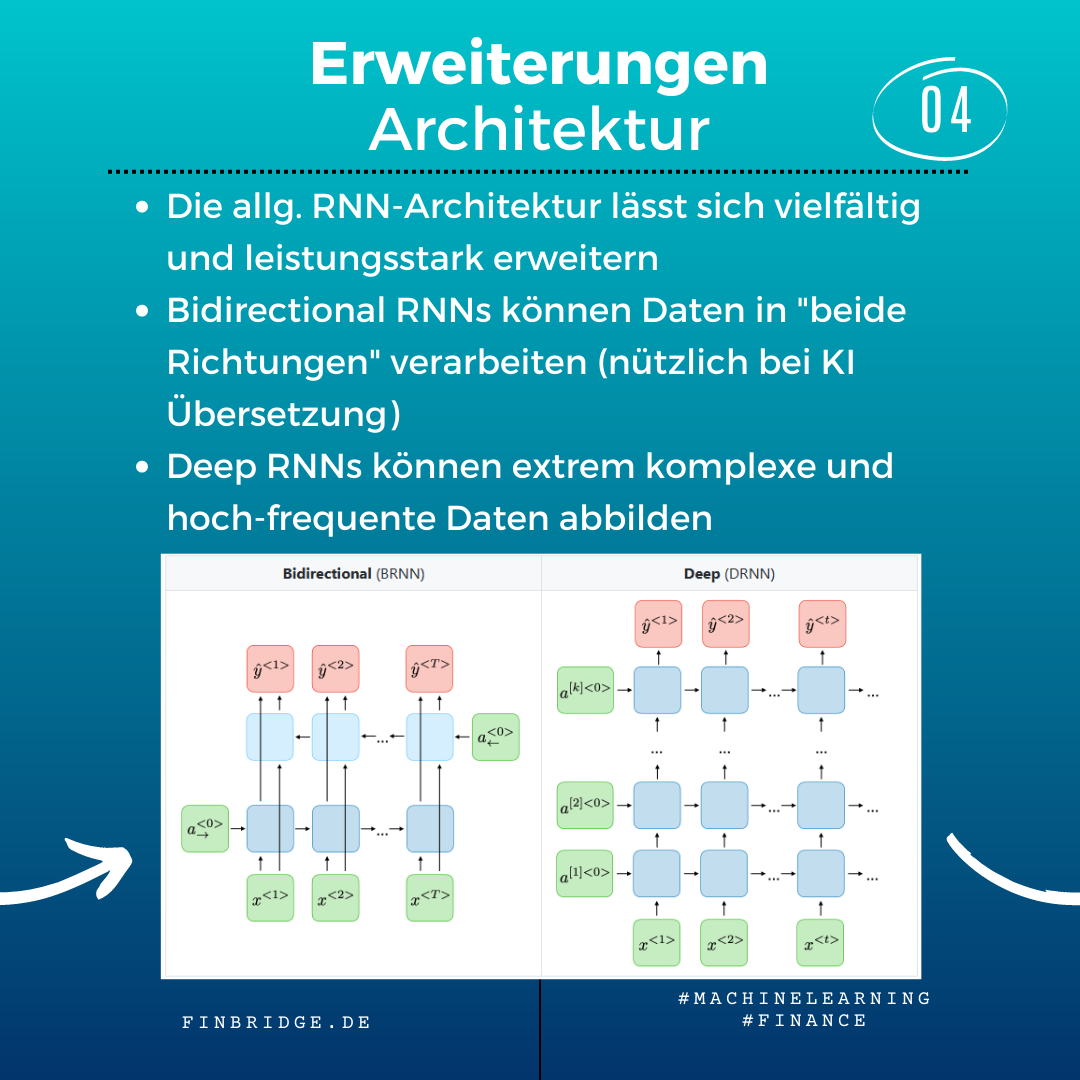
Architekturen
Auch in ihrer Gesamtarchitektur lassen sich RNNs erweitern, um komplexe Aufgaben besser lösen zu können. Ein Bidirectional RNN kann die Daten in “beide Richtungen” verarbeiten, während die meisten anderen Modelle nur eine Datenverarbeitung in eine Richtung haben. Dies eignet sich besonders für KI-Übersetzung. Deep RNNs setzen mehrere Ketten von sequentiell verknüpften Neuronen übereinander. Damit können sie selbst komplexe und verstecke Abhängigkeiten in Datenabfolgen lernen.
Fazit
Rekurrente Neuronale Netze sind eine leistungsstarke KI-Technologie, die in vielen Bereichen eingesetzt wird. Sie sind besonders nützlich für schwierige Aufgaben wie das Verstehen langer Abfolgen benötigt, wie finanzielle Zeitreihen oder natürlicher Sprache. Auch durch Ihre Neuronen und Architektur sind flexibel und mächtig erweiterbar, um solche Aufgaben zu meistern.
Der Artikel ist unterhalb in Form eines Karussells dargestellt.
![098N - Head Rekurrente Neuronale Netze [Teil 1].png](https://images.squarespace-cdn.com/content/v1/54f9ea6be4b0251d5319ad8b/1679505046198-VD84UDGP4N9CNY2QX7Q4/098N+-+Head+Rekurrente+Neuronale+Netze+%5BTeil+1%5D.png)




Erstellt von Dr. Carsten Keller und Tom Walter
Referenzen im Karussell
[1] Afshine Amidi, Shervine Amidi. "Recurrent Neural Networks". https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks.
[2] IBM. "Recurrent Neural Networks". https://www.ibm.com/topics/recurrent-neural-networks.
[*]: Link abgerufen am 02.02.2023
[**]: Die Verlinkungen verweisen auf externe Daten außerhalb unserer Domain. Trotz sorgfältiger inhaltlicher Kontrolle übernehmen wir keine Haftung für die Inhalte externer Links.
Erfahren Sie mehr zu Grundlagen:
Neugierig?
Entdecken Sie mehr über unsere Machine Learning Techniken
Wir stehen Ihnen bei Fragen zur Verfügung!