
Arten von ML in der Praxis [Teil 1]: Regression vs. Klassifikation
Was sind Regression und Klassifikation im Rahmen von Machine Learning?
Einleitung
In unserem letzten beiden Artikeln haben wir die Unterschiede zwischen Künstlicher Intelligenz (KI), Machine Learning (ML) und Deep Learning (DP) sowie die verschiedenen Arten des Lernens vorgestellt. In diesem Artikel möchten wir Regression und Klassifikation näher betrachten sowie diese miteinander vergleichen.
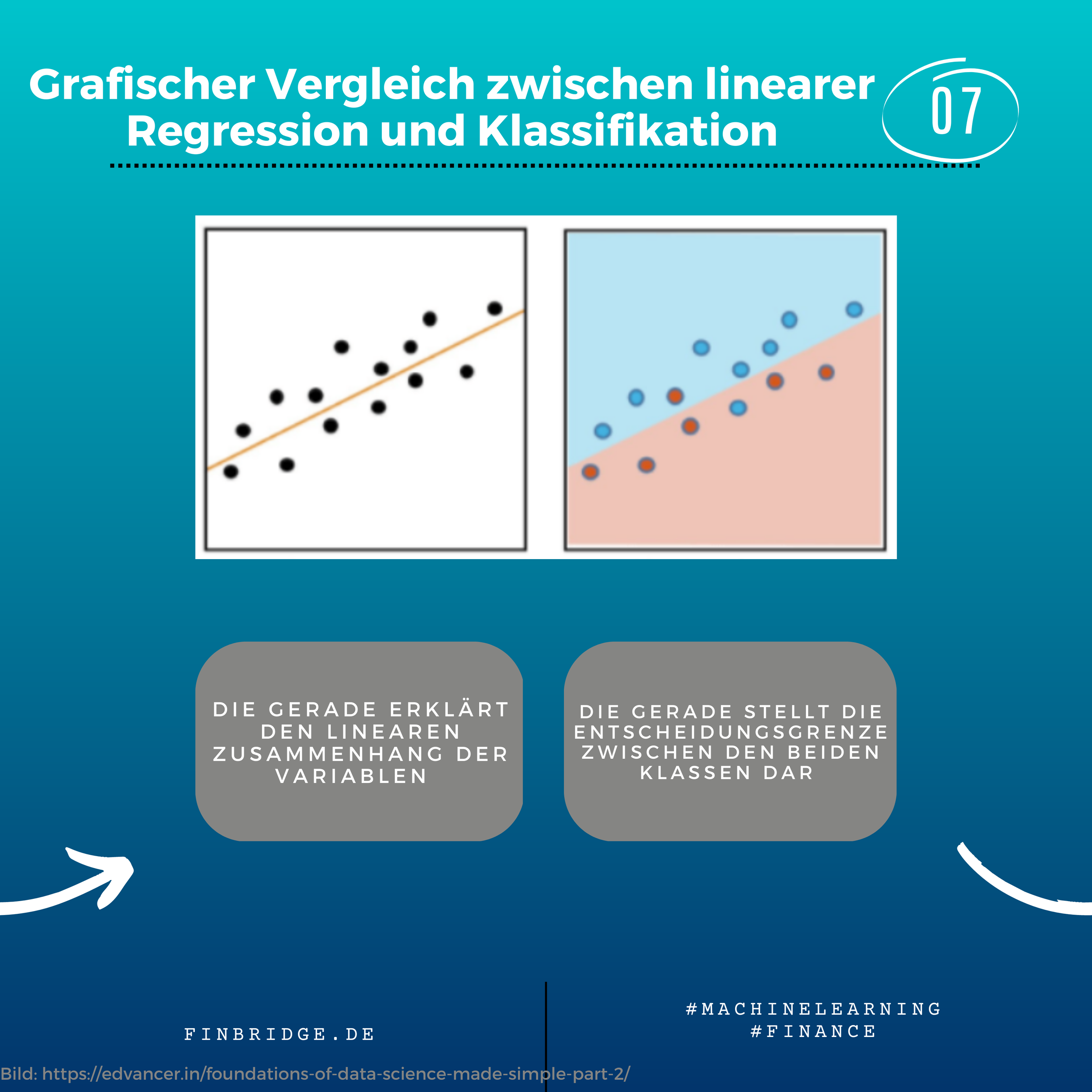
Regression
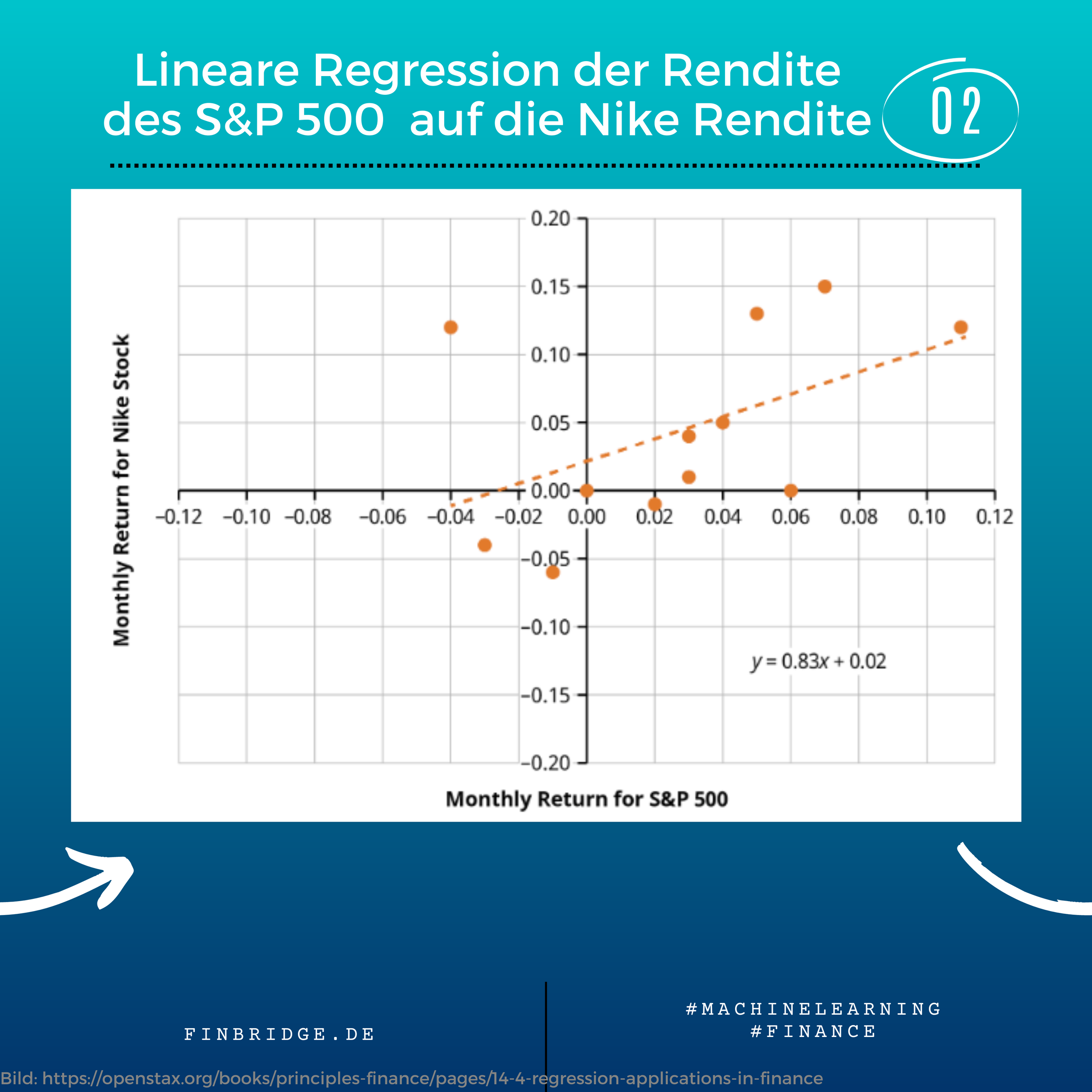
Bei einer Regression werden unabhängige Variablen (Regressoren bzw. Features) verwendet um eine numerische Variabel (Target) zu schätzen. Dabei können verschieden Datenarten wie Querschnitts-, Zeitreihen-, Panel- oder Spatialdaten verwendet werden. Bei der Modellierung von Regressionen existieren viele verschieden Ansätze. Diese lassen sich in parametrisch, nichtparametrisch oder semiparametrisch einteilen. Ein Beispiel für eine Regression ist die Schätzung eines Assetpreises basierend auf finanzwirtschaftlichen und makroökonomischen Regressoren.
Klassifikation
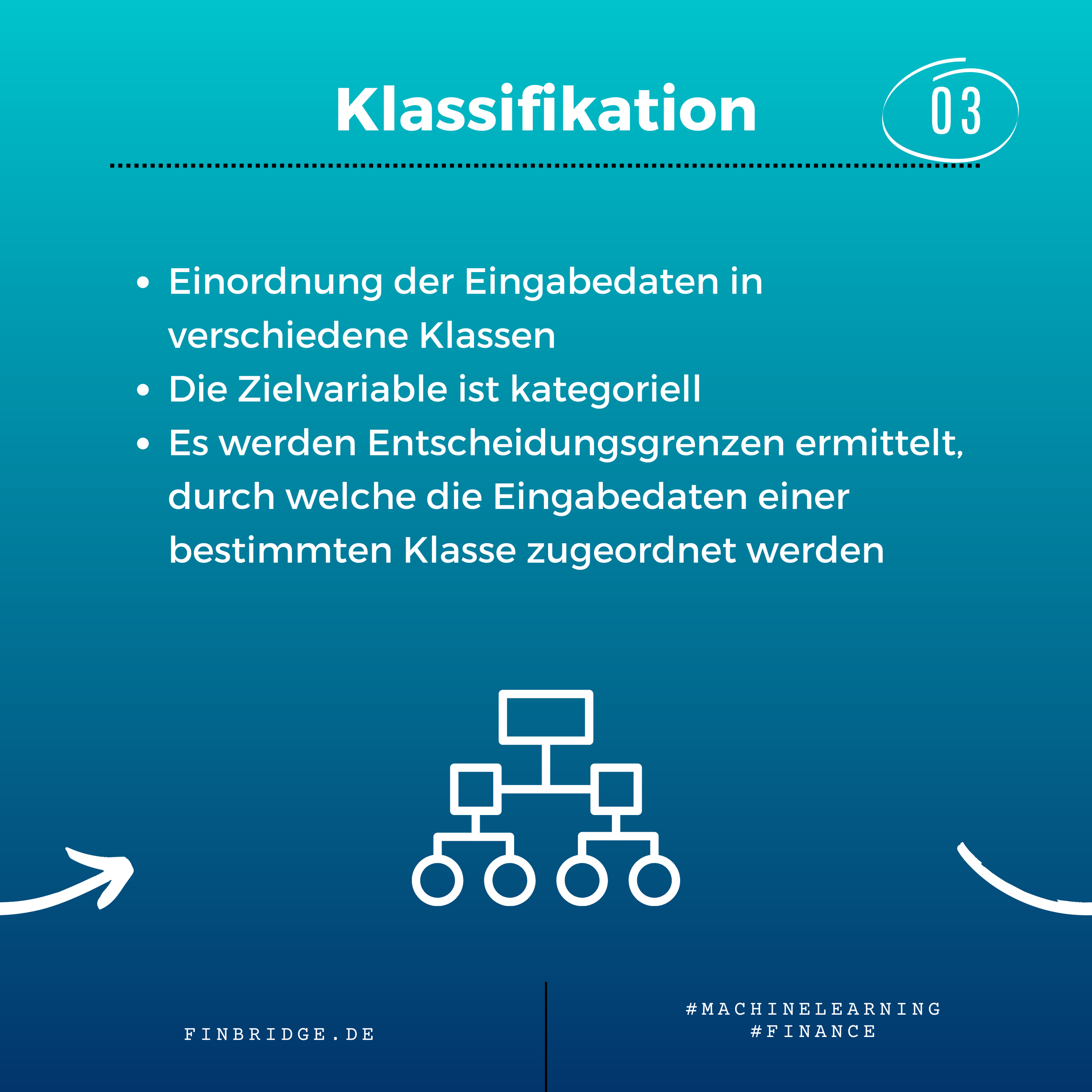
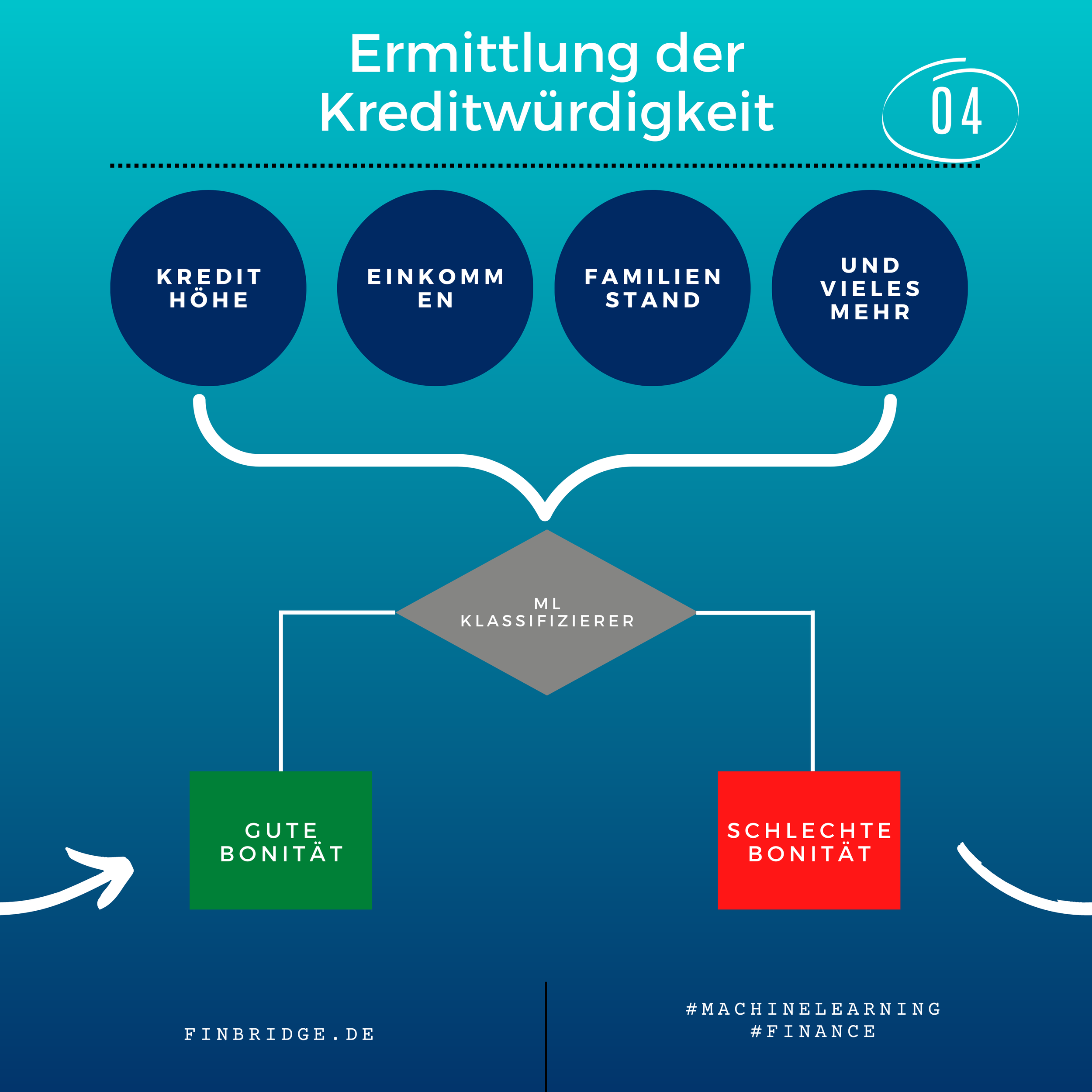
Im Gegensatz zur Regression lernt bei einer Klassifikation ein ML-Algorithmus auf Basis eines historischen Datensatzes mit verschiedenen Merkmalen (Features) und gegebenen Gruppenlabels unterschiedliche Datenpunkte voneinander zu unterscheiden und in verschiedene Gruppen einzuordnen. Danach kann das trainierte Modell benutzt werden, um neue Datenpunkte, bei denen nur die Merkmale bekannt sind, einer der Klassen zuzuordnen. Ein Beispiel für Klassifikation ist die Vorhersage der Kreditwürdigkeit eines Kunden basierend auf seiner finanziellen Vergangenheit. Außerdem kann Klassifikation dazu verwendet werden, um die Wahrscheinlichkeit zu prognostizieren, dass ein Kunde seinen Vertrag bald kündigen wird (Churn Prediction).
Gemeinsamkeiten
Beide Verfahren sind Arten des Supervised Learning und verwenden unabhängige Variablen, um eine Zielvariable zu ermitteln. Eine weitere Gemeinsamkeit ist, dass beide Ansätze es ermöglichen eine Analyse durchzuführen, wie stark sich Änderungen der Features auf die jeweilige Schätzung auswirken. Abschließend können für beide Arten unter anderem Künstliche Neuronale Netze, k-Nearest-Neighbor oder Random Forests als ML-Algorithmen verwendet werden.
Unterschiede
Es werden unterschiedliche Metriken zur Beurteilung der Präzision (z.B. R^2 im Regressions- und F-Score im Klassifikationsfall) verwendet. Bei einer Klassifikation wird eine Gruppenzugehörigkeit ermittelt. Bei einer Regression hingegen eine stetige Variable geschätzt.
Fazit
In diesem Artikel haben wir uns die Grundlagen der Klassifikation und Regression angesehen und diese verglichen. Dabei haben wir gesehen welche Arten von Problemen sie jeweils lösen können und welche Praxisbeispiele es gibt. Jedoch war dies nur ein kleiner Einblick. Es gibt noch vielfältige Anwendungen, bei denen sowohl Regression als auch Klassifikation mit Hilfe von ML-Algorithmen helfen können, Produktionsabläufe zu optimieren oder neue innovative Geschäftsfelder zu entwickeln.
Wir haben die Punkte für Sie in einem visuell ansprechenden Karussell zusammengefasst.
![092N - Head Arten von ML in der Praxis [Teil 1].png](https://images.squarespace-cdn.com/content/v1/54f9ea6be4b0251d5319ad8b/1679505219607-4KJ8NMBOEQERQ5CUJHAO/092N+-+Head+Arten+von+ML+in+der+Praxis+%5BTeil+1%5D.png)





Erstellt von Dr. Carsten Keller und Patrick T. Philipp
Links zu den Referenzen im Karussell:
[1] Regression vs. Classification: What's the Difference? (statology.org)
[*]: Link abgerufen am 10.01.2023
[**]: Die Verlinkungen verweisen auf externe Daten außerhalb unserer Domain. Trotz sorgfältiger inhaltlicher Kontrolle übernehmen wir keine Haftung für die Inhalte externer Links.
Erfahren Sie mehr zum Thema Grundlagen:
Neugierig?
Entdecken Sie mehr über unsere Machine Learning Techniken
Wir stehen Ihnen bei Fragen zur Verfügung!