
Arten von ML in der Praxis [Teil 2]: Klassifikation vs. Clustering
Was sind Klassifikation und Clustering im Rahmen von Machine Learning?
In diesem Beitrag stellen wir als Fortsetzung des Vergleichs von Klassifikation und Regression in [Arten von ML in der Praxis - Teil 1] nun den Vergleich zwischen Klassifikation und Clustering als zwei verschiedene ML-Verfahren zur Erkennung von Gruppen vor.
Einleitung
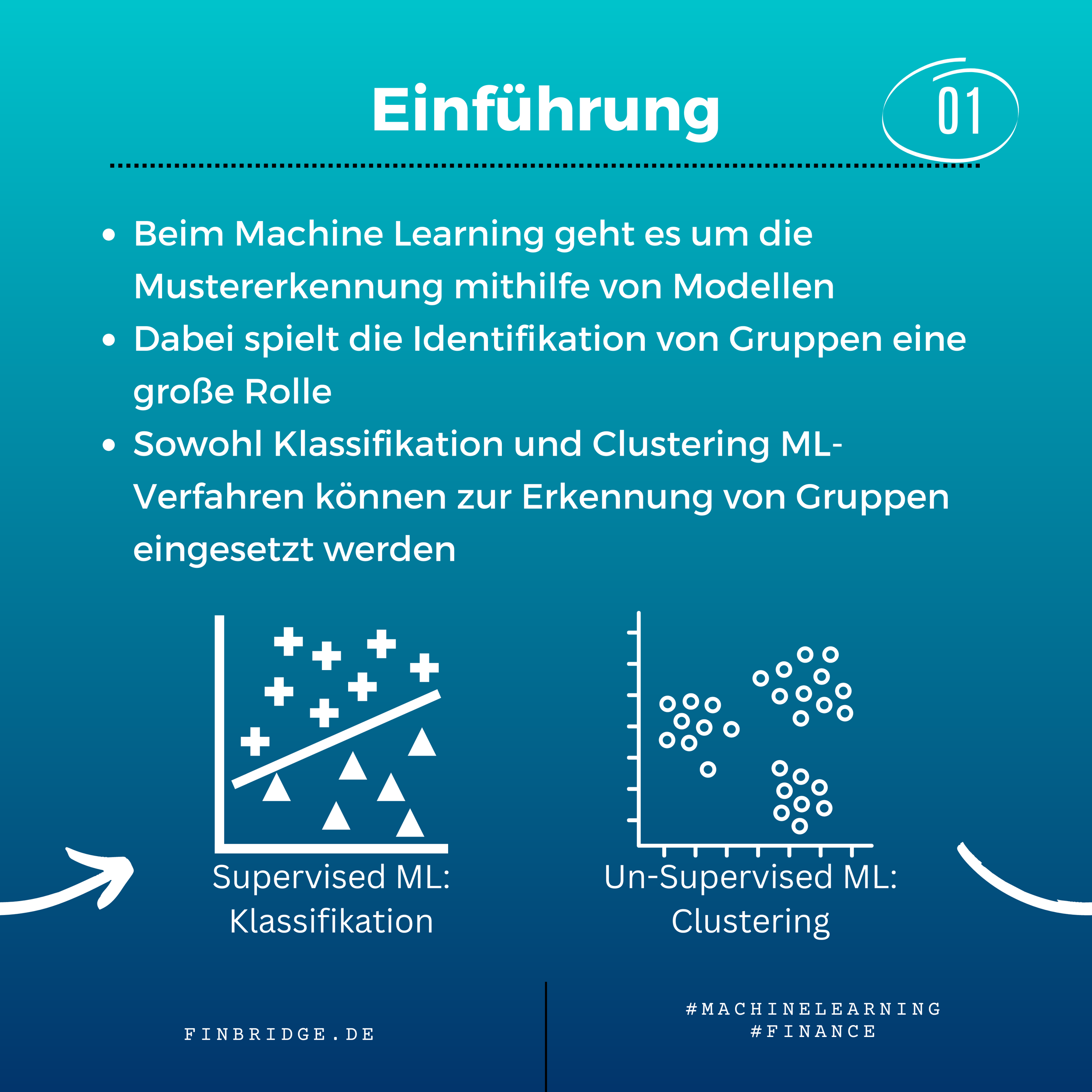
Machine Learning (ML) hat sich in den letzten Jahren zu einem wichtigen Werkzeug in vielen Branchen entwickelt. Mithilfe von ML-Modellen können große Datenmengen analysiert werden, z.B. auf vordefinierte oder auch verstecke Muster untersucht werden. Bei dieser Mustererkennung spielt Identifikation von Gruppen eine große Rolle.
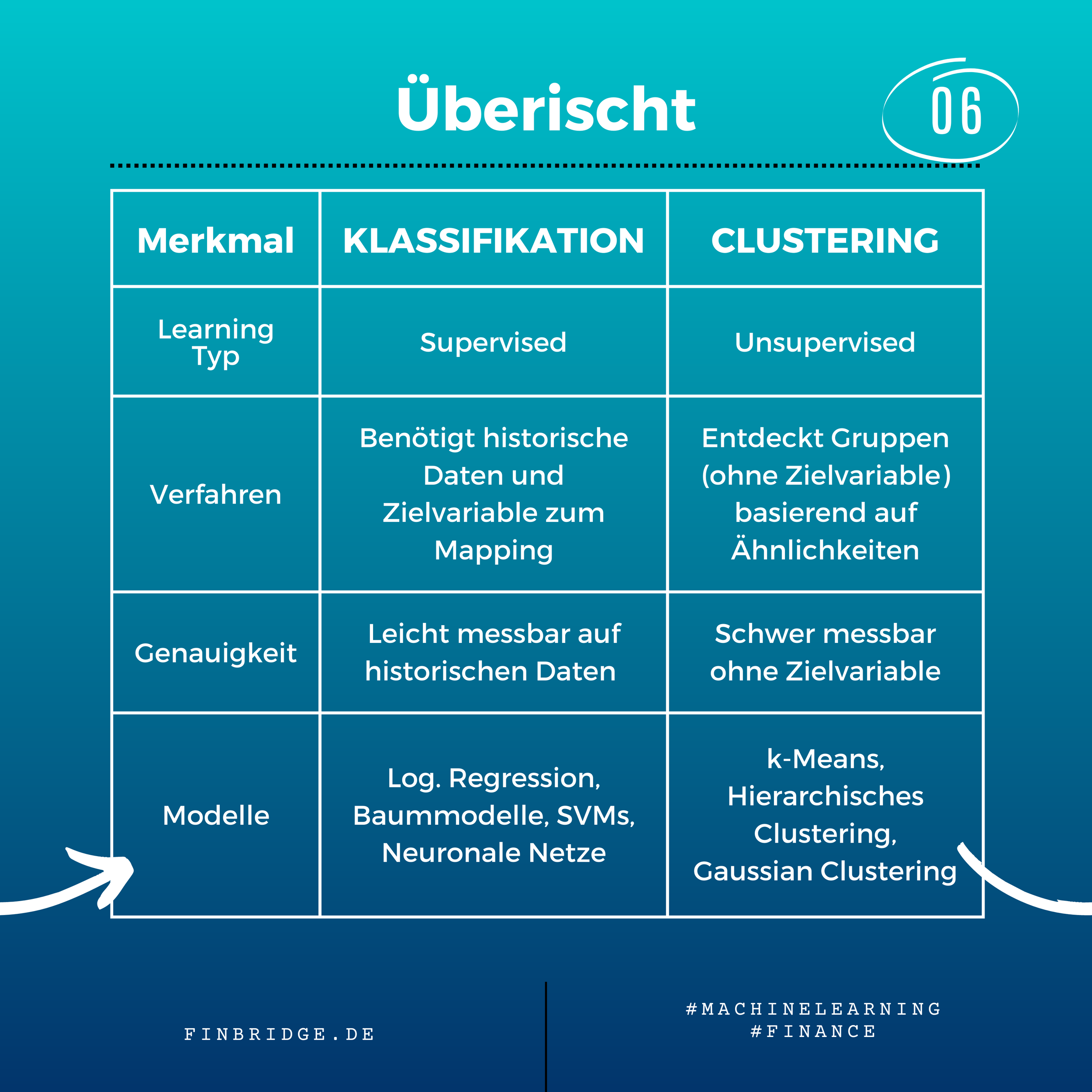
Klassifikation
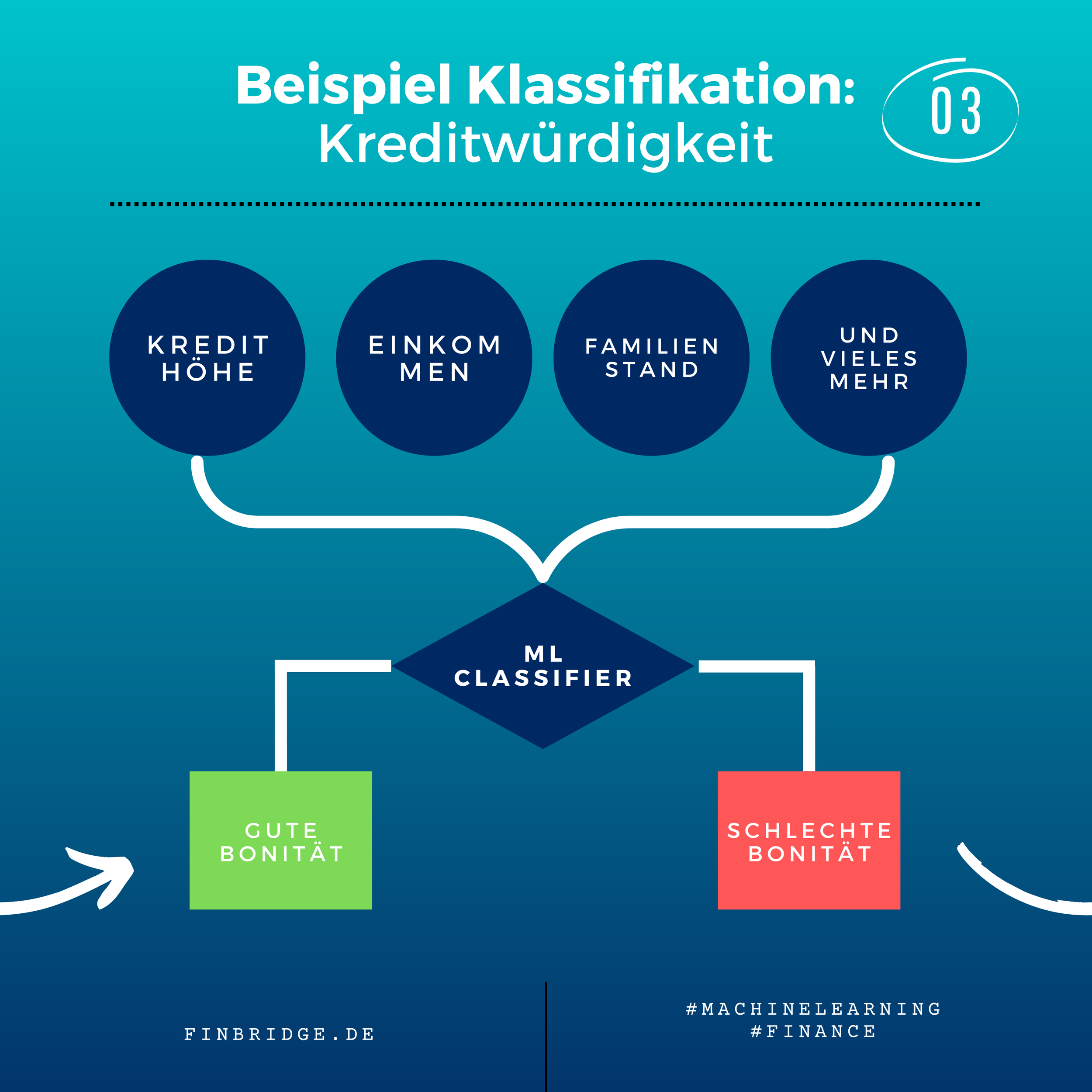
Klassifikation ist Teil des Supervised ML. Anhand eines historischen Datensatzes mit Merkmalen und vorgegebenen Gruppenlabels lernt ein ML-Modell Objekte voneinander zu unterscheiden. Danach kann das trainierte Modell eingesetzt werden, um neue Objekte zu klassifizieren. Ein Beispiel ist die Vorhersage der Kreditwürdigkeit eines Kunden basierend auf seiner finanziellen Geschichte. Klassifikation kann auch verwendet werden, um die Wahrscheinlichkeit vorherzusagen, dass ein Kunde seinen Vertrag kündigt (Churn Prediction).
Clustering
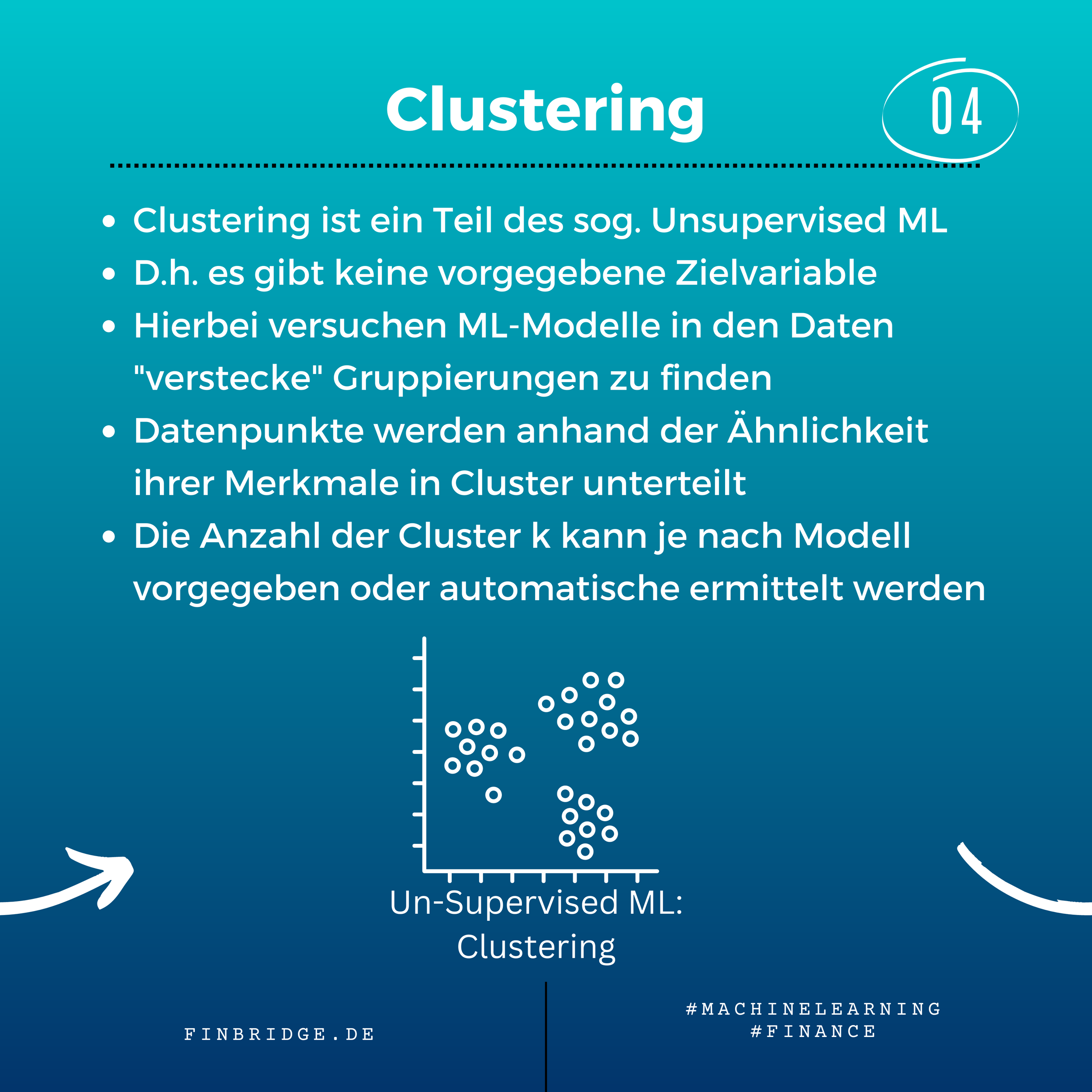
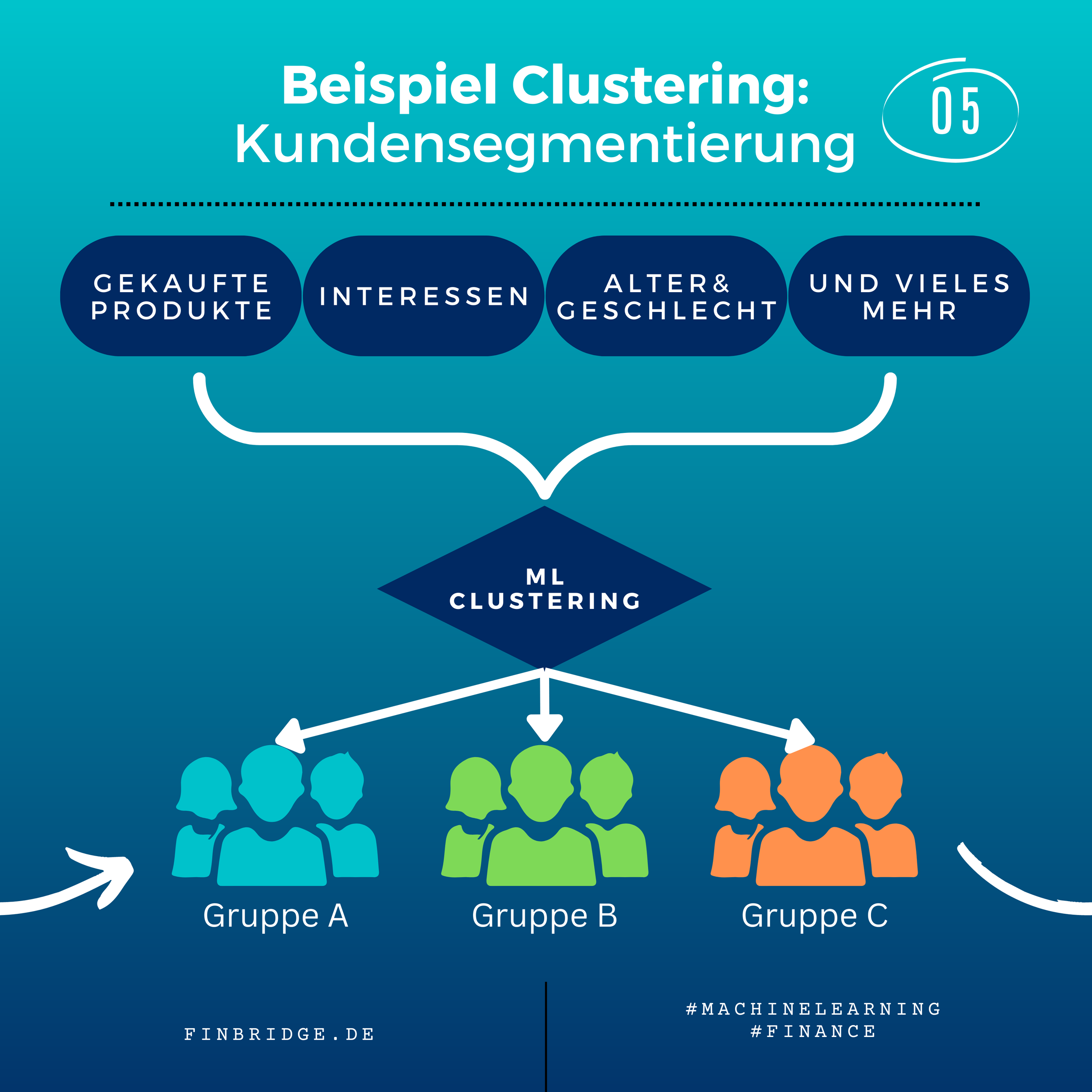
Clustering ist Teil des Unsupervised ML. Es wird dazu verwendet “verstecke” Gruppierung in Daten zu finden (und nicht, um vorgegebene Gruppen abzubilden). Dabei werden alle Datenpunkte anhand ihrer Merkmale miteinander verglichen. Ähnliche Punkte werden in denselben und unähnliche Punkte in verschiedene Cluster sortiert. Ein häufiges Anwendungsbeispiel für Clustering ist die Kundensegmentierung. Dabei werden Clustering Modelle verwendet, um Kunden in verschiedene Segmente zu unterteilen. Diese Kundensegmente können danach zu Marketingzwecken, Produktentwicklung oder Risikoschätzung weiterverwendet werden.
Fazit
Obwohl Klassifikation und Clustering beides ML-Verfahren zum Erkennen von Gruppen in Daten sind, so unterscheiden sie sich jedoch eindeutig in ihren konzeptionellen Zielen. Während Klassifikation eine Zielvariable mit Gruppenlabels braucht, um bekannte Gruppen abzubilden, braucht Clustering keine Zielvariable, sondern entdeckt zuvor unbekannte Gruppen. Durch die Nutzung dieser ML-Verfahren können somit Unternehmen wertvolle Einblicke über Gruppierungen in ihren Geschäftsdaten gewinnen und bessere Entscheidungen treffen.
Wir haben alle Punkte für Sie in einem visuell ansprechenden Karussell zusammengefasst.
![093N - Head Arten von ML in der Praxis [Teil 2].png](https://images.squarespace-cdn.com/content/v1/54f9ea6be4b0251d5319ad8b/1679518299212-6H158J2UH9D6Q04YSFGH/093N+-+Head+Arten+von+ML+in+der+Praxis+%5BTeil+2%5D.png)



Erstellt von Dr. Carsten Keller und Tom Walter
Links zu den Referenzen im Karussell:
[*]: Link abgerufen am 16.01.2023
[**]: Die Verlinkungen verweisen auf externe Daten außerhalb unserer Domain. Trotz sorgfältiger inhaltlicher Kontrolle übernehmen wir keine Haftung für die Inhalte externer Links.
Erfahren Sie mehr zum Thema Grundlagen:
Neugierig?
Entdecken Sie mehr über unsere Machine Learning Techniken
Wir stehen Ihnen bei Fragen zur Verfügung!