
Machine Learning in Finance: An innovative approach to analysing Hidden Reserves / Losses processes and other financial parameters

Photo by Marcus Lenk on Unsplash on 15.01.2021
In this article, the use of scripting and innovative machine learning techniques to automate and improve on the analysis of the Hidden Reserves and Losses (HRL) processes, which is commonly performed in the Finance departments of banks, is described. It is demonstrated how numerous quantitative effects, which define the components of the change in the HRL, can be categorised, explained, and illustrated using various machine learning algorithms.
The HRL process is considered solely to demonstrate the techniques by using an underlying example. The approach outlined in this article is not restricted to this example but is universally applicable whenever a financial parameter, whose value is influenced by various underlying features, e.g., spreads, interest curves, etc., must be analysed to determine the driving factors of its change from one point in time to another.
Introduction to the HRL process

where the market value (MV) is the fair value of an instrument and the book value (BV) is the carrying value of the instrument on the balance sheet.
The change in HRL (∆HRL) is usually calculated over a certain period, e.g., three months, and is defined as follows:

Here, ∆MV and ∆BV are given by

and

AUTOMATED DATA PROCESSING WITH RPA AND/OR PYTHON
To calculate the HRL of an instrument and particularly to analyse the reasons for changes in the HRL from one date to another, it is usually required to extract data from various systems. In this context, it is important to remember that market and book values are not just single variables but are defined themselves by various parameters (or features). For example, the book value of an instrument consists of parameters such as the notional, premium discount fees, other fee types, amortisation costs, etc. Equally, the market value of an instrument is defined by features such as the interest curve, spreads, etc.
Manual processing of the different data sources generally requires the manipulation of complex data structures in Excel sheets, which is resource-intensive and prone to inadvertent errors.
A better approach to manipulate the underlying data in a manner which makes it accessible for the machine learning algorithms described in this article, is to automate the data processing using digital resources such as Robot Process Automation (RPA) or the scripting language Python, which has built-in libraries for data manipulation. This provides more transparency, makes it easier to track changes, simplifies the identification of errors in the data processing steps that are rule-based and immune to human error and, in addition, provides significant time-savings.
The detailed description of such data manipulations is not in the scope of this article.
FEATURE ENGINEERING, SELECTION AND HRL EXPLANATION USING MACHINE LEARNING
Having built the basic requirements for transforming the raw input data into a format that can be processed by the machine learning algorithms, one can proceed to build a model that explains the changes in the HRL from one date to another based on its selected or predefined features.
In this context, the first step involves determining which features should be used in the model. One approach is to consider the theoretical relationships between the target variable (HRL) and variables that can potentially explain its change. For example, since ΔHRL can be written as the difference between the change in market value and the change in book value (see Equation 2), it makes sense to analyse the features that influence the components ΔMV or ΔBV, respectively.
In the following, the focus is on finding features that explain ΔMV, however, the techniques described may be applied in an equal measure to ΔBV.
The general formula used to calculate the market value of a financial instrument, e.g., a bond, is given by:
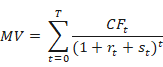
Example

It can be observed that the objective function on the right-hand side of the expression in Equation 6 represents a trade-off between the goodness of fit and the absolute value of the coefficients, controlled by the regularization hyperparameter λ. High values of λ lead to a lower sum of the absolute values of the optimal coefficients in ‖β‖1 and low values bring the coefficients closer to the ones estimated by a linear regression using an ordinary least squares (OLS) method. The optimal value of λ is chosen by cross-validation[2].
It can be shown that lasso estimator tends to yield solution vectors βlasso where some of the entries are zero. Since the entries of βlasso can be interpreted as importance weights of the features, this is a useful property that is used to select the most meaningful features from the initial set of p candidates. As already described, the optimal value of the regularization hyperparameter is selected by cross-validation and the resulting lasso regression is subsequently applied to the data set. The estimate of βlasso is sparse, meaning that some of its values are close to or exactly equal to zero. The corresponding features are regarded as not meaningful and are not used in the later stages of the analysis. Other features, whose respective coefficients are far away from zero, are considered as important.Having selected the meaningful features via lasso regression, the goal is to estimate their effect on the target variable, namely ΔHRL. This can be achieved by a linear regression model, which tries to estimate the coefficients βi in the following functional relationship:


PRACTICAL IMPLEMENTATION

In Table 1, ΔHRL calculations based on changes in book and market values are presented for two individual loans. It can be observed that Loan 1 experiences a ΔHRL reduction, because the growth of ΔBV outweighs the increase of ΔMV. On the other hand, Loan 2 shows an increase in ΔHRL since the decrease of ΔBV is greater than the decline of ΔMV.
Based on the linear model shown in Equation 9 and the two loans stated in Table 1, the effects of single features on ΔHRL can now be estimated[6]. They are presented in Figure 1 and Figure 2.

As stated above, the effect of a single feature is determined, by multiplying the coefficient of the linear model with the corresponding value of the explanatory variable. For example, if the book value change for loan 1 equals 1,253,115 EUR and the coefficient equals -0.38, then the effect of ΔBV can be calculated as

It should be noted that the approach presented in this article does not generate a perfect estimate when calculating the effects on an instrument level. This leads to differences between the ΔHRL estimated using the model presented and the actual ΔHRL. These errors cancel out on a portfolio level due to certain mathematical properties of the problem. Despite the imperfect precision, which can be improved by adding more features and/or by applying more sophisticated machine learning models, the big advantage of the linear regression approach is its interpretability, which makes the calculation of the abovementioned effects possible.
The calculation of the effects for the other variables/features can be performed in the same manner.

The (visual) representation allows to determine which effects have had the strongest influence on ΔHRL. For instance, for the first loan the change in book value is the most significant parameter (see Figure 1). In case of the second loan, the change in interest rates has the most profound effect on the target variable (see Figure 2).
Conclusion
Machine learning technology has had a profound effect on various business areas and on the financial services industry in general. The application of specific algorithms and labelled data has enabled professionals to improve on the approximation and the prediction of quantitative effects, to explain underlying effects and to increase the performance of such calculations considerably.
Together with automated rule-based pre-processing, the new techniques can give financial professionals a significant advantage when processing and identifying irregularities (or exceptions) that may be hiding in their data.
The machine learning based technique outlined in this article supports these claims and clears the path for a quick and coherent explanation of underlying effects when investigating parameters such as the fair value or book value of financial instruments. In this context, the application of the technique is not restricted to the HRL process, which is solely used as an example in this article but can be applied in all areas where the value of such parameters is determined by various underlying figures.
OUR OFFER
The ML algorithms and methodical rule-based automation approaches presented in this document allow for various possible implementation strategies for financial institutions, e.g., in processes such as the determination of HRL, hedge accounting, etc.
We would be pleased to advise you on different possible ML applications combined with automation and to help you to develop the solution which, within the professional and technical possibilities, is adequately suited for your company.














