
Proof of Concept: OCR, Künstliche Intelligenz und Zweitschriften
In unserem Hauptartikel haben wir einen Überblick über das etablierte, klassische Zweitschriftverfahren gegeben und Vorschläge zur Einsatzoptimierung der vorhandenen Ressourcen vorgestellt.
Ergänzend illustriert der folgende Proof of Concept den ersten Schritt zur Optimierung bzw. Automatisierung des Zweitschriftverfahrens durch die Digitalisierung der Arbeitsschritte der Zweitschrift-prüfenden Bank (hier: Musterbank).
Usecase Timeline
- KLASSISCHER ABLAUF -- Der Mitarbeiter der Musterbank führt eine private Wertpapiertransaktion bei seiner Depotbank durch.
- Die Depotbank versendet eine Wertpapierabrechnung an den Mitarbeiter der Musterbank –elektronisch oder per Post – sowie ein Zweitschreiben an die Musterbank,, i.d.R. per Post.
- In der Compliance-Abteilung der Musterbank wird das Schreiben durch einen Mitarbeiter bearbeitet. Im Rahmen dessen wird die Kerninformation der Wertpapierabrechnung in die Datenbank der Musterbank übertragen.
- Die Zweitschreiben werden klassifiziert, gestempelt, archiviert und für mehrere Jahre aufbewahrt,
Durch das automatisierte Zweitschriftverfahren können die Schritte unter 3. und 4. der obigen Timeline modifiziert, d.h. für den Mitarbeiter der Compliance Abteilung vereinfacht werden. Hierbei kommt ein OCR (Optical Character Recognition)- Algorithmus zum Einsatz, der digitalisierte Zweitschriften nach relevanten Informationen durchsucht und für die weitere Nutzung aufbereitet.
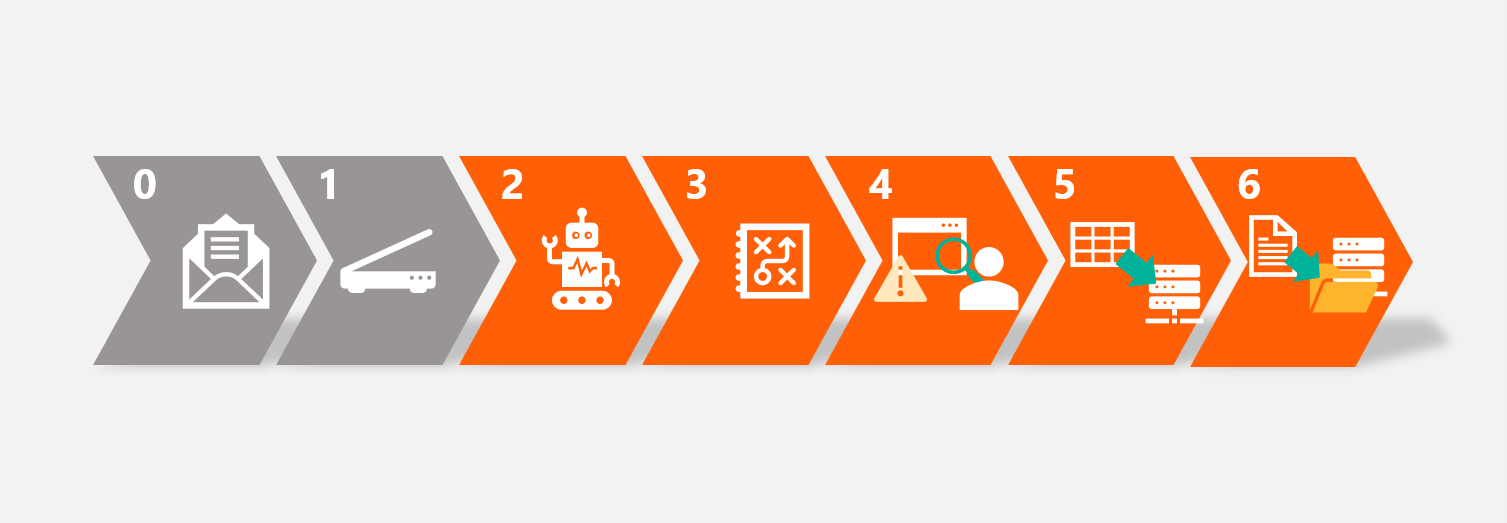
Automatisierter Ablauf des Zweitschriftverfahrens

Abbildung 1: Übersichtsskizze der einzelnen Schritte des automatisierten Zweitschiftverfahrens. Die Durchlaufzeit der Steps 1-6 pro Zweitschrift beträgt ca. 20 Sekunden im parallelisierten, vollautomatischen Durchlauf.
STEP 1: Scan und digitale Ablage der analogen Zweitschriften
Die postalisch eingegangenen Zweitschriften werden gescannt und als PDF im Arbeitsordner abgelegt. Je nach vorhandener IT-Infrastruktur kann dies bereits automatisiert oder mit manueller Unterstützung erfolgen.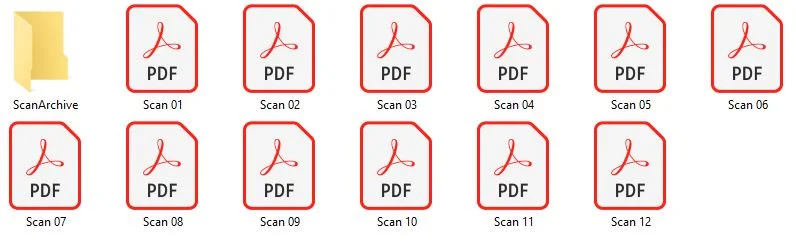
Abbildung 2: Ablage der gescannten Zweitschriften im Arbeitsverzeichnis.
STEP 2: Auswertung der in den Scandateien enthaltenen Informationen
Die einzelnen Scanfiles werden per OCR-Algorithmus nach relevanten Informationen bzw. Mustern durchsucht. Im Vorfeld müssen hierzu die benötigten Felder bzw. Informationen definiert, und das “Customizing” des Algorithmus entsprechend angepasst werden.

Abbildung 3: Beispiel eines vom Algorithmus durchsuchten Scanfiles: DIe relevanten Informationen in den identifizierten Bereichen werden erkannt und extrahiert. Quelle: Finbridge GmbH & Co. KG
STEP 3: Zwischenspeicherung & Plausibilitätsprüfung
Die Plausibilisierung erfolgt durch KI-Algorithmen und vordefinierte Prüfregeln. Als Ergebnis werden die abgelegten Datensätze klassifiziert in “vollständig erkannte" (grün) und “manuell zu bearbeitende“ (rot) Datensätze, siehe auch Abbildung 4.

Abbildung 4: Die ausgelesenen Datensätze werden im Zwischenspeicher abgelegt und einer Plausi-Prüfung unterzogen. Im Front-End werden die Datensätze mit entsprechender Markierung angezeigt: “grüne” Datensätze wurden vollständig erkannt, “rote” Datensätze müssen manuell nachbearbeitet werden.
STEP 4: Manuelle Nachbearbeitung der ROT MARKIERTEN DATENSÄTZE
Via Algorithmus nicht eindeutig auswertbare Dateien werden zur manuellen Bearbeitung bzw. Überprüfung gekennzeichnet (hier: rote Markierung). Die Datensätze können über ein eigenes Front-End manuell vervollständigt werden. Alle manuellen Bearbeitungs- bzw. Änderungsschritte werden in einem Logfile zwecks Nachverfolgbarkeit gespeichert und archiviert.

Abbildung 5: Front-End zur manuellen Bearbeitung der Datensätze, die nicht vollständig via Algorithmus ausgelesen werden konnten. Quelle: Finbridge GmbH & Co. KG
STEP 5: BEREITSTELLUNG DER EXTRAHIERTEN DATEN ZUR WEITEREN NUTZUNG
Die extrahierten Daten werden vom Automatisierungstool in das gewünschte Format umgewandelt und zur Archivierung an die Bestandssysteme übergeben. Je nach Zielsystem bzw. -format zur Archivierung der Daten kann es notwendig sein, eine entsprechende Schnittstelle aufzubauen um einen vollautomatischen Prozess zu ermöglichen.

Abbildung 6: Export der relevanten Daten im gewünschten Dateiformat (z.B. Excel, csv) und Layout zwecks Transfer, Weiterverarbeitung und/oder Archivierung in Bestandssystemen. Quelle: Finbridge GmbH & Co. KG
STEP 6: UMBENNENUNG, KLASSIFIZIERUNG UND SPEICHERUNG DER PDF-DATEIEN AUF DEN FILE-SERVERN
Die gescannten, bearbeiteten Zweitschriften werden mit sprechenden Dateinamen versehen und zur Archivierung abgelegt.
Abbildung 7: Ablage und Archivierung der verarbeiteten, mit sprechenden Bezeichnungen versehenen Scandateien. Quelle: Finbridge GmbH & Co KG.
Vorteile des automatisierten Zweitschriftverfahrens
80% bis 90% aller Zweitschriften werden vom OCR-Algorithmus problemfrei erkannt und komplett automatisiert ausgewertet. Die übrigen, nicht eindeutig identifizierten Datensätze werden dem Mitarbeiter über ein Front-End zur manuellen Bearbeitung zur Verfügung gestellt.
Die gescannten Zweitschriften werden automatisch umbenannt, klassifiziert und auf die File-Server gespeichert.
Das automatisierte Zweitschriftverfahren ermöglicht eine Reduzierung des gesamten Zeitaufwandes um bis zu 80% im Vergleich zum “klassischen” Zweitschriftverfahren.
Der automatisierte Prozess führt folglich zu einer signifikanten zeitlichen Entlastung der Mitarbeiter.
Unser Angebot
Gerne unterstützt Sie Finbridge GmbH & Co. KG bei der Automatisierung des Zweitschriftverfahrens in ihrem Hause.
Unser Angebot umfasst u.A. ein Automatisierungstool, das wir per Customizing auf ihre individuellen Bedürfnisse anpassen und in die bestehende IT-Infrastruktur einbetten. Das enthaltene Front-End ermöglicht die einfache manuelle Nachbearbeitung von Sonderfällen, bei denen die erforderlichen Informationen nicht eindeutig per Algorithmus ausgelesen werden konnten. Gerne Erarbeiten wir bei Bedarf auch eine individuelle Schnittstellenlösung zur Archivierung der Zweitschriften im gewünschten Zielsystem.
Unsere Experten profitieren von langjähriger Erfahrung bei der Umsetzung verschiedenster IT-Projekte und begleiten Sie gerne bei der Umstellung und Optimierung der bestehenden Prozesse. Sprechen Sie uns gerne an!
Autoren: Henrique Schulz, Till Fischer, Christoph Herbert
IHRE ANSPRECHPARTNER
Mehr über künstliche Intelligenz



Das Zweitschriftverfahren ist der Prozess zur Offenlegung von Wertpapierumsätzen der eigenen Mitarbeiter einer Bank bei Drittinstituten.
Die Übermittlung dieser Informationen erfolgt durch Versand einer Kopie der Ausführungsanzeigen bzw. Abrechnungen durch die depotführende Stelle an die Compliance-Abteilung des Arbeitgebers.
In der Compliance-Abteilung des Arbeitgebers werden die Dokumente zunächst manuell in die hauseigene IT-Struktur übernommen und anschließend inhaltlich geprüft und archiviert










